The vast majority of code any academic researcher will undertake relates to data analysis including any preparatory transformations and cleaning. Most code outside of research and data analysis tends to fall in the realm of CRUD (create / read / update / delete) applications, APIs (Application Programming Interfaces) and process automation. It’s unlikely many academics will be developing software or APIs for consumption but rules-based automation is one area that could be useful.
Advanced LLMs are also effective at explaining and teaching code, particularly with Python given the huge volume of python code available on the public internet to train on. As Bail (2023: 6) writes:
“One of the most important contributions of Generative AI to social science may therefore be expanding access to programming skills... A ChatGPT user, for example, can ask the model to explain what is happening in a single line of code, or how a function operates”
Can Generative AI Improve Social Science?
This section focuses on a simple rules-based automation coding example using Python where GPT4 can act both as a tutor and provide working code to extract specific data from a specific website at a regular interval. In this case, the example is extracting basic information from the UKRI website for latest funding opportunities and appending to a local spreadsheet. This is a useful beginner example of basic web scraping (Note: many firms do not permit scraping of their data, which can risk overloading servers when done at scale in addition to extracting proprietary data, and either set rules to prevent it being easily done, or may block your IP or pursue legal action in severe cases. The example below is from a UK government-managed website explicitly designed to make data publicly available) since both the URL and the HTML elements containing the information are clearly structured and predictable. In this case the basic filters I’ve added on the UKRI’s Funding Finder webpage are any open and upcoming ESCR grants which results in this URL:
https://www.ukri.org/opportunity/?keywords=&filter_council%5B%5D=818&filter_status%5B%5D=open&filter_status%5B%5D=upcoming&filter_order=publication_date&filter_submitted=true
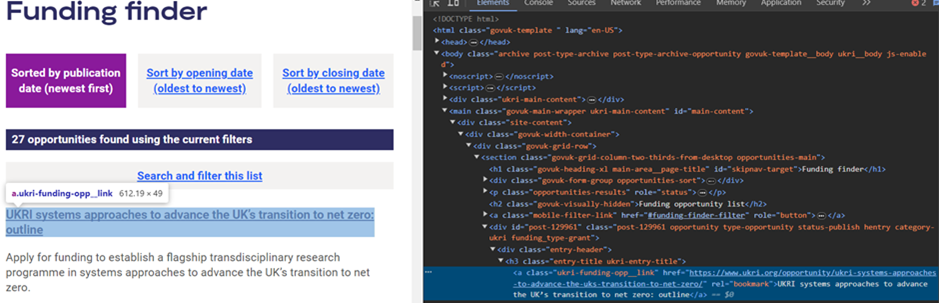
An example search result looks like this:

Here is a full conversation with GPT4o where the prompt makes clear that the user has no experience with this kind of task, and it helpfully provides the required information, particularly regarding in terms of inspecting the underlying HTML components in order to determine the underlying identifiers of specific elements of information that are of interest. This is the key first step to any kind of web scraping, since webpages are unique in their structure and how components are named, but someone new to this concept wouldn’t even know to ask and might get themselves into a frustratingly confusing situation, so here the prompt is explicitly asking the LLM to ask the user for more information given they are a beginner. In the case of the UKRI website, when right clicking on the grant title and clicking ‘inspect’, it shows the underlying identifier which is “ukri-funding-opp__link”. On any other webpage this would be called whatever the web designer decided, so this manual step is required. But once you have it you can paste it into the class or title placeholder in the script GPT4o has provided below.
Prompt:
I need help creating a Python script to extract information from a UKRI grant funding opportunities webpage.
The webpage shows a list of grant opportunities, and for each grant, attached is a screenshot so you can see what it looks like. I want to extract:
1. The title of the grant
2. Total fund
3. Maximum award
4. Closing date
I want to save this information into an Excel file on my computer. I don't have experience with web scraping or HTML, so I need guidance on how to get started.
Can you help me by:
1. Explaining what information you need from me about the webpage to create this script?
2. Providing step-by-step instructions on how to find this information on the webpage, assuming I only know how to use a web browser?
3. Creating a Python script template that I can fill in with the information I find?
4. Explaining how to install any necessary Python libraries and run the script?
Please ask me questions about the webpage if you need more details to provide accurate instructions.
Response:
Step-by-Step Instructions
1. Information Needed from the Webpage:
o HTML Structure: The HTML tags or classes used for the title, total fund, maximum award, and closing date.
o URL: The webpage URL where the grants are listed.
2. Finding Information on the Webpage:
o Open the webpage in your web browser.
o Right-click on the title of the grant and select "Inspect" or "Inspect Element." This will open the browser's developer tools.
o Look at the HTML code to identify the tags and classes used. Note these details down.
o Repeat this for the total fund, maximum award, and closing date.
3. Python Script Template:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the webpage with grant opportunities
url = "YOUR_WEBPAGE_URL_HERE"
# Send a GET request to fetch the webpage content
response = requests.get(url)
web_content = response.content
# Parse the webpage content with BeautifulSoup
soup = BeautifulSoup(web_content, 'html.parser')
# Extract the required information
grant_titles = []
total_funds = []
maximum_awards = []
closing_dates = []
# Modify these selectors based on your inspection
title_selector = 'YOUR_TITLE_SELECTOR'
total_fund_selector = 'YOUR_TOTAL_FUND_SELECTOR'
maximum_award_selector = 'YOUR_MAXIMUM_AWARD_SELECTOR'
closing_date_selector = 'YOUR_CLOSING_DATE_SELECTOR'
# Find all elements that match the selectors
titles = soup.select(title_selector)
funds = soup.select(total_fund_selector)
awards = soup.select(maximum_award_selector)
dates = soup.select(closing_date_selector)
# Loop through the elements and extract text
for title, fund, award, date in zip(titles, funds, awards, dates):
grant_titles.append(title.get_text(strip=True))
total_funds.append(fund.get_text(strip=True))
maximum_awards.append(award.get_text(strip=True))
closing_dates.append(date.get_text(strip=True))
# Create a DataFrame to store the extracted data
data = {
'Title': grant_titles,
'Total Fund': total_funds,
'Maximum Award': maximum_awards,
'Closing Date': closing_dates
}
df = pd.DataFrame(data)
# Save the DataFrame to an Excel file
df.to_excel('grant_opportunities.xlsx', index=False)
print("Data has been extracted and saved to grant_opportunities.xlsx")
4. Installing Necessary Python Libraries:
-
- Requests: To fetch the webpage content.
- BeautifulSoup (bs4): To parse the HTML content.
- Pandas: To create a DataFrame and save it to an Excel file.
- Openpyxl: To handle Excel files with Pandas.
Running the Script
1. Install Python and Pip (if not already installed):
o Download and install Python from python.org.
o Pip is included in modern versions of Python.
2. Install the Required Libraries: Open your terminal or command prompt and run the command mentioned above to install the necessary libraries.
3. Create and Run the Script:
o Save the provided Python script in a file, e.g., scrape_grants.py.
o Open your terminal or command prompt.
o Navigate to the directory where your script is saved.
o Run the script using the command:
python scrape_grants.py
This script will fetch the webpage, extract the required information, and save it into an Excel file named grant_opportunities.xlsx.
If you need help identifying the HTML selectors from the webpage, feel free to provide the URL or more details about the structure of the HTML elements.
Human response to requests:
Thank you. I clicked on 'inspect element' to identify the entire result 'box' for one of the results, and the result is below. Does this help you figure out how to make the script identify the values to be extracted?
<div id="post-143494"> <div> <h3 class="entry-title ukri-entry-title"> <a class="ukri-funding-opp__link" href="https://www.ukri.org/opportunity/core-research-challenges-in-digital-twinning-for-crisis-resilience/" rel="bookmark">Core research challenges in digital twinning for crisis resilience</a> </h3> </div><!-- .entry-header --> <div> <p>Apply to lead an interdisciplinary research programme in digital twinning which seeks to aid decision makers in their role of strengthening the resilience of transport networks – including increasing capability before and during crisis management to address a range of threats and hazards.</p> </div><!-- .entry-content --> <div> <dl class="govuk-table opportunity__summary"> <div class="govuk-table__row"> <dt>Opportunity status: </dt> <dd class="govuk-table__cell opportunity-cells"><span class="open opportunity-status__flag">Open</span></dd> </div> <div> <dt class="govuk-table__header opportunity-cells">Funders: </dt> <dd> <a class="ukri-funder__link" href="https://www.ukri.org/councils/epsrc/">Engineering and Physical Sciences Research Council (EPSRC)</a>, <a class="ukri-funder__link" href="https://www.ukri.org/councils/ahrc/">Arts and Humanities Research Council (AHRC)</a>, <a href="https://www.ukri.org/councils/esrc/">Economic and Social Research Council (ESRC)</a>, <a href="https://www.ukri.org/councils/nerc/">Natural Environment Research Council (NERC)</a>, <a href="https://www.ukri.org/councils/stfc/">Science and Technology Facilities Council (STFC)</a>, <a href="https://www.ukri.org/councils/bbsrc/">Biotechnology and Biological Sciences Research Council (BBSRC)</a>, <a class="ukri-funder__link" href="https://www.ukri.org/councils/mrc/">Medical Research Council (MRC)</a> </dd> </div> <div class="govuk-table__row"> <dt>Funding type: </dt> <dd class="govuk-table__cell opportunity-cells">Grant</dd> </div> <div> <dt>Total fund: </dt> <dd class="govuk-table__cell opportunity-cells">£4,375,000</dd> </div> <div> <dt class="govuk-table__header opportunity-cells">Maximum award: </dt> <dd>£4,375,000</dd> </div> <div class="govuk-table__row"> <dt>Publication date: </dt> <dd>27 June 2024</dd> </div> <div class="govuk-table__row"> <dt>Opening date: </dt> <dd class="govuk-table__cell opportunity-cells"> <time datetime="2024-06-25T09:00:00">25 June 2024 9:00am UK time</time> </dd> </div> <div> <dt class="govuk-table__header opportunity-cells">Closing date: </dt> <dd> <time datetime="2024-09-05T16:00:00">5 September 2024 4:00pm UK time</time> </dd> </div> </dl> </div><!-- .entry-meta --> </div>
LLM response:
Great! This information helps to pinpoint the exact HTML structure and classes you need to target in your web scraping script. Here’s how you can adjust the provided Python script to use this structure:
Adjusted Python Script
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the webpage with grant opportunities
url = "YOUR_WEBPAGE_URL_HERE"
# Send a GET request to fetch the webpage content
response = requests.get(url)
web_content = response.content
# Parse the webpage content with BeautifulSoup
soup = BeautifulSoup(web_content, 'html.parser')
# Extract the required information
grant_titles = []
total_funds = []
maximum_awards = []
closing_dates = []
# Modify these selectors based on your inspection
title_selector = 'h3.entry-title a.ukri-funding-opp__link'
total_fund_selector = 'div.govuk-table__row:contains("Total fund:") dd.govuk-table__cell'
maximum_award_selector = 'div.govuk-table__row:contains("Maximum award:") dd.govuk-table__cell'
closing_date_selector = 'div.govuk-table__row:contains("Closing date:") dd.govuk-table__cell time'
# Find all elements that match the selectors
titles = soup.select(title_selector)
funds = soup.select(total_fund_selector)
awards = soup.select(maximum_award_selector)
dates = soup.select(closing_date_selector)
# Loop through the elements and extract text
for title, fund, award, date in zip(titles, funds, awards, dates):
grant_titles.append(title.get_text(strip=True))
total_funds.append(fund.get_text(strip=True))
maximum_awards.append(award.get_text(strip=True))
closing_dates.append(date.get_text(strip=True))
# Create a DataFrame to store the extracted data
data = {
'Title': grant_titles,
'Total Fund': total_funds,
'Maximum Award': maximum_awards,
'Closing Date': closing_dates
}
df = pd.DataFrame(data)
# Save the DataFrame to an Excel file
df.to_excel('grant_opportunities.xlsx', index=False)
print("Data has been extracted and saved to grant_opportunities.xlsx")
Explanation of the Script
Libraries: requests, BeautifulSoup (part of bs4), pandas for data handling, and openpyxl for Excel output.
URL: Replace "YOUR_WEBPAGE_URL_HERE" with the actual URL of the webpage you are scraping.
Selectors:
title_selector: Targets the grant title.
total_fund_selector: Targets the total fund amount.
maximum_award_selector: Targets the maximum award amount.
closing_date_selector: Targets the closing date.
Extraction:
Uses BeautifulSoup to parse the HTML and select the elements based on the specified selectors.
Extracts and strips the text from each element.
DataFrame:
Stores the extracted data in a Pandas DataFrame.
Saves the DataFrame to an Excel file.
Installing Necessary Python Libraries
Run the following command in your terminal to install the required libraries:
pip install requests beautifulsoup4 pandas openpyxl
Running the Script
Save the script as scrape_grants.py.
Open your terminal or command prompt.
Navigate to the directory where the script is saved.
Run the script:
python scrape_grants.py
This will create an Excel file named grant_opportunities.xlsx with the extracted grant information.
If you need further adjustments or run into any issues, feel free to ask!
Here’s the resulting Excel file from that script, which worked first time (thanks to careful prompting for the LLM to require the user to identify the HTML needed for the script to work - those with less experience will likely face setbacks and require bug fixing queries with the LLM):
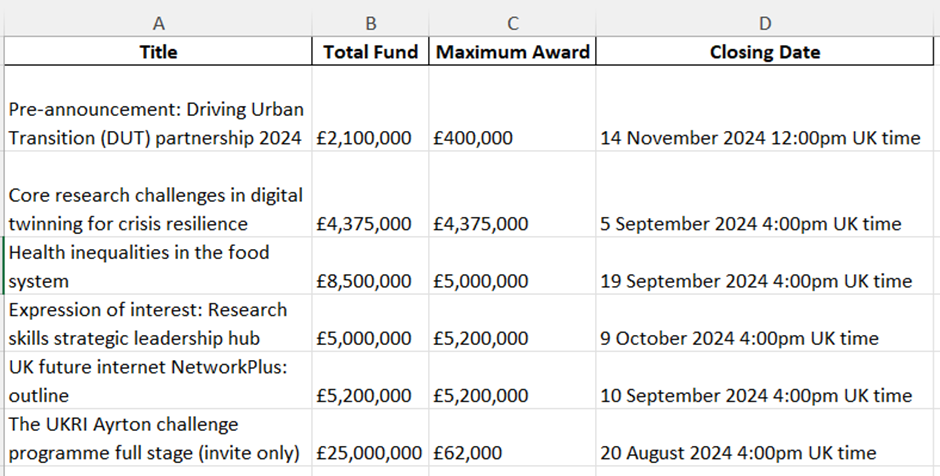
Generally, the shorter and simpler the code, and the clearer and more explicit the prompt, the better results LLMs like GPT4/o and Claude 3/3.5 generate.
One of the best parts about using generative AI for code is that because code by definition follows very strict, robotic rules, verification is not only easy but the whole point is to test it out as soon you get the output. If you run code to extract information from the above webpage and the resulting spreadsheet has the closing date in the column where the grant title should be, this is far easier to verify and correct than, for instance, an LLM’s response to a question asking, for instance, the most important underlying factor behind the 2009 European debt crisis.