Generative AI in its broadest sense refers to AI systems that create new content, predominantly text but also images, audio and video, based on users’ natural language prompts. Before 2022, the most impressive AIs (at least as far as widespread public awareness is concerned) were narrow in both scope and value, e.g. Alpha Go or IBM Watson winning Jeopardy. Most research or work-related examples were in the domains of prediction, classification and basic natural language processing like sentiment analysis or chat bots informed by a specific, curated knowledge base. Narrow but extremely effective AI ‘recommendation engines’ proliferated in the corporate and social media spheres. The idea of a more generalised artificial intelligence was still mostly theoretical until a major advancement that combined neural networks (in particular the transformer model) and colossal investment in computational hardware and data. This led to the development of GPT (Generative Pre-trained Transformer), with Open AI’s GPT-3 being the first instance of a chatbot, powered by a Large Language Model that was capable of convincingly human-like textual interactions, including entirely novel language outputs.
Large Language Models
By far the most prominent form of generative AI now, and likely for the foreseeable near future given the dominance of language in most human interactions that we would associate with any kind of intelligence (and certainly for the majority of scholarly research), is the Large Language Model (LLM). The basic idea behind LLMs is fairly simple to grasp: for any given text, what is the likely text that would follow it, given the word associations in the training dataset? This Medium article illustrates the basic concept (though in an extremely simplified way). 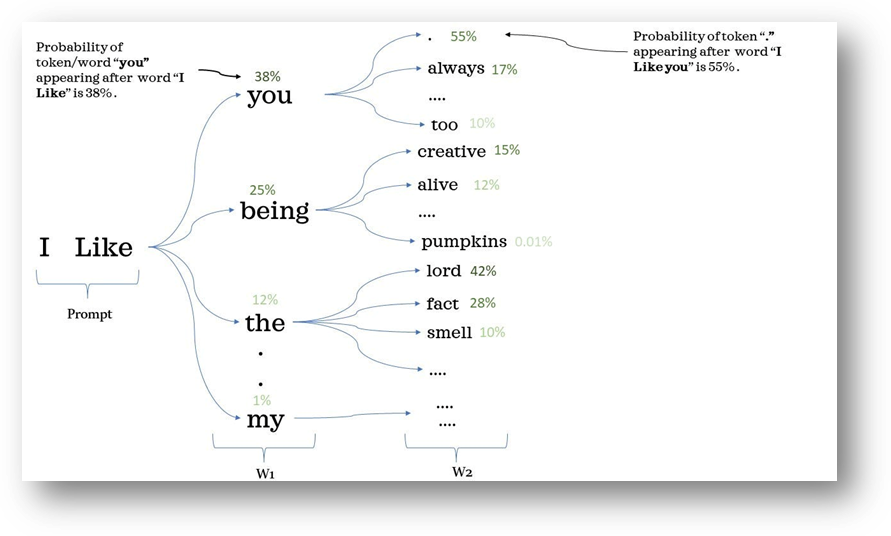 GPT4 was trained on almost all the public text on the internet (speculated to be in the trillions of words), and its objective was to predict the next sequence of words as well as it can. In order to be able to achieve effective prediction, it has to somehow internalise a model of the human world, which confers an advanced – though still limited and in many ways alien – understanding ability, emerging mostly from the correlations in text it has been trained on. In a sense, the text itself can be considered a limited projection of the world and by implication of humanity. A fascinating report published by Anthropic in 2024 entitled "Mapping the mind of a large language model”, offers promising early insights into how LLMs create their own internal abstractions which ‘fire’ in relevant sections of text.
GPT4 was trained on almost all the public text on the internet (speculated to be in the trillions of words), and its objective was to predict the next sequence of words as well as it can. In order to be able to achieve effective prediction, it has to somehow internalise a model of the human world, which confers an advanced – though still limited and in many ways alien – understanding ability, emerging mostly from the correlations in text it has been trained on. In a sense, the text itself can be considered a limited projection of the world and by implication of humanity. A fascinating report published by Anthropic in 2024 entitled "Mapping the mind of a large language model”, offers promising early insights into how LLMs create their own internal abstractions which ‘fire’ in relevant sections of text.

While these insights representing exciting – and critically important for long term human-AI value alignment – early steps, advanced LLMs are still much too complex and advanced to provide the kind of explainability or audit trail many AI regulations have required. The fundamentally stochastic and unpredictable nature of LLM outputs also means strict research reproducibility is difficult to achieve beyond very simple tasks such as classifications with clear boundaries.
A useful way to think about LLMs is to treat them as a well-read, confident and eager-to-please ‘intern’ who often misunderstands and gets things wrong. They are not deterministic machines. What they excel at is in producing plausible-looking text, which is a remarkable technological breakthrough in itself (and which has necessitated moving the goalposts on the Turing Test), but it doesn’t even begin to constitute a valid or reliable source of knowledge. Plausible looking text outputs are often correct, so it’s forgivable if people accept its outputs at face value. But LLMs can and do produce bizarrely incongruous ‘hallucinations’ where they confidently output entirely incorrect assertions.
'Reasoning'
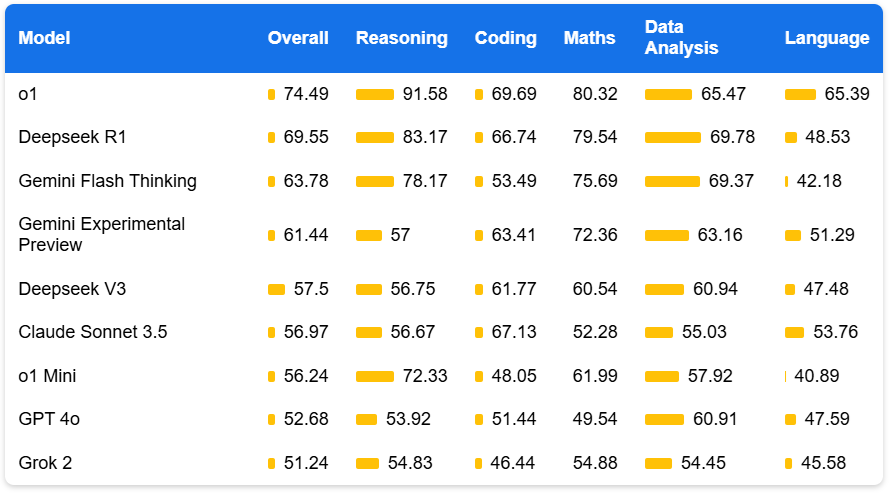
In September 2024, a new kind of generative AI model was announced by Open AI: o1. This was followed by Google Gemini's 'flash thinking' and Deepseek R1. This type of model incorporates chain of thought 'reasoning' (to be thought of more pattern matching of steps that are more likely to lead to correct answers based on the training data) out of the box. It has opened up new opportunities for using LLMs on more challenging tasks that require correct answers or some known measure of quality. Here are the January LLM rankings from Livebench.Ai, with the top 3 dominated by the new reasoning models:
Potential future directions
The major AI players have recognised the inherent deficits of LLMs that train on vast human-produced text and simulating ‘answers’ based on the messy source and the hugely constraining impact of maximum context length windows. While scaling up to the tune of training on trillions of words is the number one reason LLMs are as good as they are now, efforts are being made to use generative AI to generate synthetic training data, iteratively evaluated (including by more advanced reasoning models), to maximise the quality of underlying data. The hope is to reduce contamination of organically generated human errors to bring increased reliability, accuracy and overall quality of outputs. An early paper entitled, “Textbooks are all you need” (Gunasekar et al. 2023) showcased impressive results given the tiny corpus of training data and complexity of the model (1.3bn parameters, compared to GPT4 which, while not official, is said to have over a trillion). ‘Garbage in, garbage out’ has always been true and it is certainly the case for LLMs trained on almost the entirety of public human-produced text.
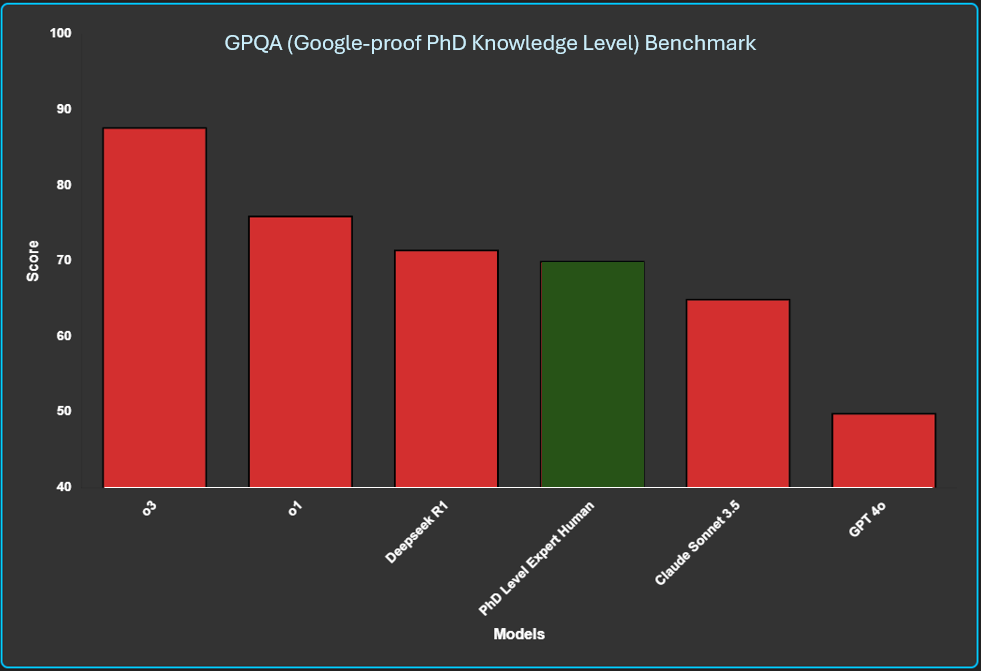
In December 2024, Open AI announced impressive results of their new o3 model which, among other benchmarks, was said to have represented a genuine breakthrough in reasoning by the creators of the ARC AGI Prize, who had previously stated that it would be several years before an LLM architecture could perform well on these tasks. o3's Codeforces result places it higher than 99.8% of global competitive coders, who as a group are already above average. Its GQPA (google proof, PhD-level science questions, in the sense that a typical PhD in the field would score about 70%) score exceeded all expectations:
In January 2025, Deepseek R1's reasoning model went viral thanks to using a much simpler and cheaper training reward approach and curating a smaller but higher quality training dataset. This ability to reach near-o1 level results at a fraction of the computing cost created such a shock that Nvidia's stock price - the giant GPU manufacturer known as the modern-day AI equivalent of the shove provider during a gold rush - dropped more than 15% in a single day.
Agentic AI
There are also early – though very limited and unreliable – manifestations of what some refer to as ‘agent models’ that can handle long term multistep tasks incorporating planning, reflection, decisions, short term memory and interacting with digital software in a meaningful way. In late 2024, Anthropic shared a preview of 'Computer Use', incorporating Claude's vision capabilities and general intelligence with mouse and keyboard control to take actions on a screen interface designed for humans. The general unpredictability of AI tools means they should be treated with extreme caution, as evidenced by this quote from Anthropic reporting Claude seemingly getting bored of the task it was asked to do:

In January 2025, Open AI released a limited prevew of their 'Operator' agent, very similar to Claude Computer Use, and available only to Pro license holders. Early reviews have been mixed, noting common issues with misclicks due to vision capabilities not quite being pixel perfect, or neglecting to ask the user for confirmation at vital steps. Despite the flaws, AI firms have a lot of incentive to make this kind of tool work, given the scale of mundane visual software interface work done around the world. If they can get it right, the potential negative impact on employment could be substantial.
Other examples of Generative AI
The most capable non-text based generative AI technology available to the general public is for image generation and image interpretation / analysis, with applications like Flux (available as part of the paid Twitter / X plan), Dall-E 3 (available in Microsoft Copilot as well as Chat GPT Plus / Team) and Midjourney currently being the best quality models that are widely available and easy to use.
As far as social science research value is concerned, image generation AI is mostly limited to enhancing blogs, presentations or other knowledge exchange communications. It’s worth reminding researchers to exercise caution around ongoing legal cases regarding intellectual property and how AI models including image generation were trained on public human-created content. Currently, the vast majority of AI image generation is in the realm of art, rather than, say, technical diagrams. That said, for diagrams which are programmatically generated, the more advanced LLMs are capable of producing accurate flowcharts and infographics – here are some example using the Claude 3.5 Sonnet ‘artifacts’ (interactive web output display) feature, something Chat GPT is now able to achieve thanks to their new Canvas feature with web preview:
Example flow diagram generated by Claude Sonnet 3.5 based on the above section on history and current state of generative AI:
(right click and open in new tab for higher resolution)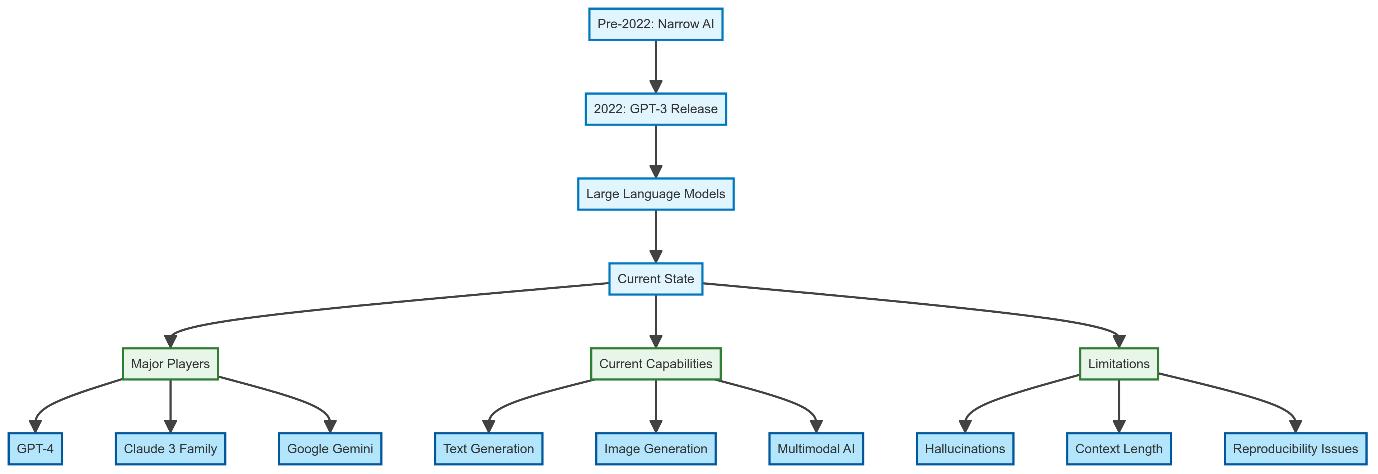
Example infographic generated by Claude Sonnet 3.5 based on the above section on potential future developments: 
Text to speech
Synthesised speech from text content has been around for a while with limited quality, but the ability to combine generative AI to create original speech with realistic and emotive voices (currently ElevenLabs are the leader in this field, though in March 2024 Open AI released early results of a highly advanced model including troublingly realistic voice cloning) could be very valuable, for instance summarising an academic article with a realistic human voice or even having a real time verbal conversation about an academic article, or creating experimental simulations of focus groups to better inform question design. In September 2024, Google released Notebook LM, which among other features has a free 'podcast generation' tool based on whatever content you provide it. The quality and authenticity of the generated podcasts are remarkable, as well as being genuinely entertaining. These have strong potential for KEI long term especially once voice and tone customisation are enabled.
Multimodality
Demos from May 2024 from Open AI (GPT-4o – for ‘omni’) and Google’s Project Astra showcase impressive real time, realistic multimodality including native voice input and output, as well as live video input (based on repeated timed screenshots) and nuanced interpretation of affect in voice and even facial expressions, that can dramatically change how AI can be used for everyday tasks as well as education. In the social sciences, the potential for having an AI ‘see what you can see’ and provide commentary and input at the same time may provide research value but gaining consent for human subjects may prove difficult. Many people will find the idea of AI analysing their emotions from their face and voice in real time uncomfortable. Resistance could even extend to more benign visual analysis such as human movement in urban settings to inform space planning. There is significant potential for researching revealed preferences through visually analysing actual behaviour in humans, but it’s difficult to imagine examples beyond highly controlled settings where participants are fully aware and consent, which of course may ‘contaminate’ the validity of data given humans behave differently when they know they’re being observed.
Recommended Reading
Bail, C. A. (2023). Can generative AI improve social science? (Pre-print).
Burger, B., Kanbach, D. K., Kraus, S., Breier, M., & Corvello, V. (2023). On the use of AI-based tools like ChatGPT to support management research. European Journal of Innovation Management, 26(7), 233-241.
Dwivedi, Y. K., Kshetri, N., Hughes, L., Slade, E. L., Jeyaraj, A., Kar, A. K., Baabdullah, A. M., Koohang, A., Raghavan, V., Ahuja, M., & Albanna, H. (2023). “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. International Journal of Information Management, 71.
Korinek, A. (2023). Generative AI for economic research: Use cases and implications for economists. Journal of Economic Literature, 61(4), 1281-1317.
Lenhard, W., & Lenhard, A. (2023). Beyond human boundaries: Exploring the proficiency of AI technology and its potential in psychometric test construction. (Pre-print).
Manning, B. S., Zhu, K., & Horton, J. J. (2024). Automated social science: Language models as scientist and subjects. (working paper). Massachusetts Institute of Technology and Harvard University.
Pack, A., & Maloney, J. (2023). Using generative artificial intelligence for language education research: Insights from using OpenAI's ChatGPT. TESOL Journal, 57, 1571-1582.
Rahman, M., Terano, H. J. R., Rahman, N., Salamzadeh, A., & Rahaman, S. (2023). ChatGPT and academic research: A review and recommendations based on practical examples. Journal of Education, Management and Development Studies, 3(1), 1-12. https://doi.org/10.52631/jemds.v3i1.175.
Watkins, R. (2023). Guidance for researchers and peer-reviewers on the ethical use of large language models (LLMs) in scientific research workflows. AI and Ethics, 1-6.
Xu, R. et al. (2024). AI for social science and social science of AI: A survey. Information processing and management, 61(3).