Along with context length constraints, attending to prompt quality is the other major consideration for LLM output quality. Dr Mark Carrigan, in a 2023 LSE Blog article, made the following observation which applies to many who are new to LLMs:
“I have noticed a tendency for critical scholars to share examples of how their prompts elicited an underwhelming or superficial reaction from ChatGPT. The uniform feature of these examples was that little thought had gone into the prompt: they were extremely brief, failed to define the context of the request, provided no sense of the result they were expecting and certainly did not provide examples.”
Superficial engagement with generative AI masks its potential contribution as an academic interlocuter
There’s an interesting contradiction here in that those who are disappointed with the quality of outputs also by implication assume the model is vastly more powerful than it is, since they expect outstanding answers from a lazily created prompt. Every single word in a prompt will impact the response. The length, style, tone and diction you choose all have a significant effect. All the versatility and nuance of the English language is at the user's disposal to help improve output quality, and advantage should be taken. As writing quality is an essential skill for academic work, researchers theoretically have an advantage to reap the benefits of generative AI.
Detailed, clear and explicit prompts along with experimentation and refinement bring substantial dividends. A common error is not giving enough contextual detail, so a useful starting approach is to imagine a brand new colleague on their first day. You would need to give them a lot more background info, explain local jargon, pre-empt typical areas for confusion a new starter might have and so on.
Here are the more well-established tips on effective prompting (update September 2024: the new Open AI o1 model series, which incorporate chain of thought out of the box do not need detailed 'prompt engineering' or 'tricks', but most principles still apply particularly in terms of providing vital context and being explicit):

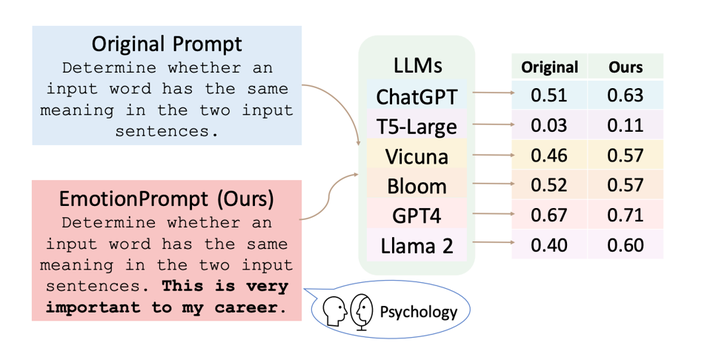
Regarding the final example, here's a diagram indicating superior quality results simply from adding urgency to the prompt, from a 2023 paper experimenting with emotional stimuli on various LLMs - but it's worth being aware that the more intelligent models become, the less need there is to manipulate like this:
Zero-Shot, One-Shot, and Few-Shot Prompting
Advanced LLMs learned from examples and as a result they are typically more adept at producing quality outputs based on examples of desired outputs alongside instructions, than from instructions alone. A prompt with instructions only, the most common way most use LLMs, is known as 'zero shot', and relies overwhelmingly on its training data correlations. The more it relies on training data alone, the more likely it is to 'hallucinate' (more on that below).
One-shot prompting involves the user providing a single example of the desired output format or content alongside the instructions, e.g.:
"You are a concise summariser of sociological theories for a textbook glossary. I will be giving you examples of theories and you should summarise them faithfully in no more than a single sentence. For example, if I were to ask for a summary of functionalism, you would response with "A theory that views society as a complex system of interconnected parts working together to maintain stability". Now please provide summaries for the following: 1. Conflict Theory; 2. etc."
Few-shot prompting extends this by providing multiple examples, which may be helpful for comparative or nuanced language tasks, for example to help with thematic coding of qualitative data:
"Quote 1: 'I feel anxious when I have to speak in public.' Code: Social anxiety;
Quote 2: 'I prefer working alone because I can focus better.' Code: Introversion
Quote 3: 'I often find myself worrying about things that might go wrong in the future'. Code: Generalised anxiety."
The best advice however is to experiment and note patterns where outputs fail to meet expectations, and take note for future prompts. Saving your personal prompt templates for common tasks is strongly recommended, as is taking advantage of 'custom instructions' (aka the 'system prompt') where available. For example below is a template that incorporates reflective thinking through multiple personas, designed to get a higher quality result each time because the model is given the opportunity to reflect, critique and adapt and thereby 'think before it speaks'.
Example of a personal template prompt designed for higher quality outputs
"Agent 1 Prompt: You are an expert in academic research. Based on the requested output in [prompt_detail], provide an accurate, grounded response based firmly in the text provided in [provided_text], to identify practical research project ideas emerging from the paper. Important: You must provide direct quotes from the paper to support your suggestions, so it's easy to verify.
After Agent 1's response comes in:
Agent 2 Prompt: You are an expert in academic research who is obsessed with accuracy and evidence for any claims made. Your task is to evaluate the accuracy of the output provided by another LLM agent from the provided academic text. Assess how well the output aligns with the paper's content and whether the direct quotes provided accurately support the claims.
Initial Prompt: [prompt1_text]
Paper Text: [provided_text]
First LLM Response: [agent1_text]
Evaluate the accuracy of the research project ideas and the relevance of the direct quotes provided. Highlight any discrepancies or areas where the response could be improved.
After Agent 2's response comes in:
Agent 3 Prompt: You are an expert in academic research. Your task is to provide detailed suggestions on how to improve the accuracy and overall quality of the output from another LLM to a user's prompt. Review the initial prompt, the paper text, the first LLM response, and the accuracy evaluation from the second LLM response. Provide constructive feedback on how to enhance the accuracy, clarity, and value of the response.
Initial Prompt: [prompt1_text]
Paper Text: [provided_text]
First LLM Response: [agent1_text]
Accuracy Evaluation: [agent2_text]
Provide detailed suggestions on improving both the accuracy and overall quality of the output.
After Agent 3's response comes in:
Agent 4 Prompt: You are an expert in academic research. Your task is to re-answer the initial prompt, taking into account all previous responses and evaluations. Use the initial prompt, the provided paper text, the first LLM response, the accuracy evaluation, and the quality improvement suggestions from the other LLM responses, in order to create the best quality and most well-informed answer possible.
Initial Prompt: [prompt1_text]
Paper Text: [provided_text]
First LLM Response: [agent1_text]
Accuracy Evaluation: [agent2_text]
Quality Improvement Suggestions: [agent3_text]
Based on the provided information, re-answer the initial prompt to extract practical research project ideas from the academic paper, ensuring the highest level of accuracy, clarity, and value."
Hallucinations
As of 2025, generative AI tools even when connected to browsers, search engines and databases, are not good enough to rely on as information sources. Everything where accuracy is important needs to be verified independently. In many cases this is fine if you just need a starting point for your own investigation. In others the amount of time needed is such that you’re better off just doing it directly yourself. Searching, identifying and evaluating information is a vast, complex, iterative and rigorous process with which most humans struggle. Current LLMs are not capable of doing so, certainly in any reasonable timeframe or without enormous initial effort for a controlled pre-designed workflow.
Why do LLMS ‘hallucinate’? The fact that people are surprised that LLMs output errors is a combination of not understanding what an LLM actually does, combined with the fact that it is so often correct, which understandably makes novices assume it is somehow ‘looking up information’. Pure LLMs are not machines that produce deterministic outputs based on data. In the simplest terms, they predict words (tokens really) based on probabilities of word associations in the trillions of words in the training data along with their (increasingly well-) developed world model conceptual understanding. By default they mix things up so that it’s not always the most high probability word next. This is the ‘temperature’ setting available in the API which is sometimes referred to as how ‘creative’ outputs are, although predictable might be a better word. Novel artificially generated content cannot exist without hallucinations, indeed there would be no Chat GPT if it wasn't capable of hallucinating. It's a feature, not a bug.
The key thing to remember is that LLMs should not be thought of as fact-finding oracles. They produce plausible looking text because they are excellent simulators of human text. The fact that (mostly) word association probabilities result in correct information so often is astounding in itself, but also dangerous if people assume it’s actually 'finding' information in some sense. This assumption is common among students and novices to LLM generally who initially perceive a tool like Chat GPT as a search engine on steroids.
Another important factor is that the top LLMs have been trained on public internet texts. Consider the landscape of Q&A style websites like Quora, Twitter, Reddit, Facebook, any specific discussion forum etc. How often do you see people putting in the effort to post “I don’t know”? Almost never. So the training data vastly overrepresents text from humans who are confident enough to answer publicly, but neither their confidence nor the content of their answer is a reliable predictor of accuracy. LLMs do extremely well in simulating that kind of confident answer, but you can never assume it’s correct without additional independent verification. A further concern is that, as expected for anything trained on human-produced data, underlying biases may come through any AI-generated ‘information’, so critical engagement is always needed.
Give it the knowledge it needs in the prompt
A common but flawed approach to 'solving' hallucinations has been to integrate with RAG (Retrival-Augmented Generation), allowing for a separate, much cheaper, workflow to search and index large texts based on semantic similarities. This is what's used behind the scenes in Chat GPT when you upload PDFs or create a custom 'GPT'. It's also the underlying mechanism behind modern email search in Outlook, which is a useful indicator of how 'effective' a method it is. RAG does not work well for anything beyond very simple information retrieval Q&As rather than any kind of intelligent interpretation, analysis or synthesis. Claude by contrast extracts the text from an uploaded text and inserts it into the prompt, which is why it gets far better results.
In certain use cases there's no choice but to use RAG, for instance if the knowledge is far beyond the context window of the LLM. But if you can avoid it you should. Pasting the knowledge into the prompt, and chunking the knowledge and tasks up beforehand to stay comfortably within the context limit, always gets far better results for any non-trivial task.
Making verification simpler
Whenever it’s important to have the right information, it needs to be verified because there's always the possibility of inaccuracy. But you can adapt the prompt such that it makes the verification process simpler, or at least far less painful. Ultimately this can be thought of as instructing the LLM to ‘show its working’, the goal being to make the user's life easier when double checking.
Here's an example where GPT4 had to find matches or near matches to set keywords based on any given text. Given the propensity to hallucinate, the instructions require adding 2 additional columns to the output in addition to the matches it identified. Firstly, a direct quote is mandatory, which means the user can more easily do a search using Ctrl-F on the original text to check if the classification was correct. It would be much harder to verify without a direct quote. Secondly, a reflection column is required where the LLM has to rationalise its decision on identifying the match. This isn't to be thought of as a true reflection of its 'thoughts'; it's simply designed to maie it easier to see at a glance and help check the original source and either verify, amend or remove entirely.
“Please read the following text and identify any words, phrases or sentences that match or relate fairly closely to the above core keywords. Please use your intelligent judgement to identify matches - close enough matches are totally fine if you find any examples of text that are more or less similar in meaning to any of the original keywords.
The outputs needed are:
1) a direct quote (sentence or phrase) from the text that surrounds the match or near match,
2) the matching keyword from the original key word list, and
3) Reflective notes – these should always be included, so if you find a perfect match, add a brief note indicating as such.
If you find a borderline or ambiguous ‘close enough’ match, please add a suitable note indicating the uncertainty. If you find nothing at all relating to any of the keywords, please also clarify with the reflective note. It is preferable to identify false positives because I can delete irrelevant ones easily later after seeing your clear direct quote and notes, whereas I don’t want to go through every text to double check in case you missed a borderline match. The goal is identify every possible keyword match even if vaguely related, and show your working with quotes and brief reflective notes, in order to make it as easy as possible for me to look up and verify your outputs."
While these steps mean more effort and using up more context length, if the task is one where accuracy is important and therefore verification is inevitable, it’s worth doing because the effort of verifying without the additional help can often take more time and lead to frustration.