“Perhaps the most promising task that could be outsourced to Generative AI is content analysis of text-based data”
Can Generative AI Improve Social Science?
The above quote is no exaggeration, the potential value of advanced LLMs for qualitative analysis is enormous. The most significant drawback to qualitative textual analysis is practical: the sheer scale, time and cognitive effort required to perform tasks like thematic coding. While no LLM can be expected to code text data perfectly first time – and nor should you want it to, since the kind of depth needed to interpret, analyse and infer from qualitative data requires intense cognitive engagement – it can be a significant time-saver once you have your set of codes tried and tested on an initial sample. It’s then a matter of giving the LLM explicit and strict instructions on how to code various chunks of text, always with a default 'other' category for cases it can't confidently interpret, and accepting that manual verification will be required.
Here's a real example of a prompt to provide up to 4 thematic codes for anonymised student survey qualitative comments:
“I have a 5-column table below, 4 of which are empty which I'd like your help with please. The first column contains anonymised qualitative student feedback comments for my university department. I want you to act as a qualitative analyst coding the themes of each comment. You should assign at least one theme code to each comment, and up to a maximum 4. If none of the existing codes below, you can simply leave it blank, only assign codes with which you are very confident. Please present the results to me in a 5-column table format so I can paste into Excel.
These are the available thematic codes you are allowed to use:
Teacher quality and engagement
Networking and Career Opportunities
Interdisciplinary Learning
Facilities
Skill Development
Engaging content
Sense of Inclusion
Extracurricular Activities
Personal development
Strikes and disruptions
Communication and Clarity
Assessment and Feedback
Course organisation
Pressure and Stress”
For larger datasets this would be a task better suited with a Python script to the Open AI GPT4 API, given the need for repeated analysis without going over the context limit. But within the Chat GPT Plus interface we were able to do this by splitting the data into a dozen smaller chunks which didn’t take too long at all.
While the results weren’t perfect, the users were happy with over 90% of the codes it had assigned, and correcting the few errors didn’t take much effort. The strict instructions on what codes it was allowed to use helped a lot to avoid it getting too creative. But GPT4 does tend to have a ‘mind of its own’ and sometimes fails when trying to be helpful. Below is an example of a personal project where the goal was for GPT4 to assign a genre to each of a large list of UK chart songs, using only a pre-determined list of genres contained in data files:
“You are a knowledgeable and concise music genre classifier. You are given a list of songs identified by Artist and Song Title. Classify each song into one and only one primary genre from the following list: {genre_list}. Provide only the genre name as the answer with no additional conversational text. The output you produce must be in JSON array format like this: “[{"Artist": "APACHE INDIAN FT FRANKIE PAUL", "Song": "RAGGAMUFFIN GIRL", "Genre": "Reggae"}, {"Artist": "PORTISHEAD", "Song": "SOUR TIMES", "Genre": "Trip Hop"}, {"Artist": "BOYZ II MEN", "Song": "THANK YOU", "Genre": "R&B/Soul"}]”. Provide a single genre classification from the list provided for each song. If it's difficult to choose, just pick one plausible option. Here are the songs: {sample_song_list}”
Despite the clear instructions to choose a plausible option if it wasn’t obvious, it still occasionally returned results like this rather than a single genre from the list as requested:
“Please note that some songs, particularly older ones, can span multiple genres or may not fit neatly into modern genre classifications. Additionally, the classification can also vary based on interpretation and context. For example, "The Ying Tong Song" by The Goons could be considered Novelty or Comedy, which isn't explicitly listed but might fall under Pop for the purposes of broad categorization. If "Comedy" were acceptable as a genre for the purpose of this task, please let me know, and I will update the classification accordingly”
The above is a useful illustration of the distinction between how we think of computers traditionally, as deterministic, rule-following machines, versus advanced, probabilistic and fundamentally ‘helpful’ LLMs. People are often shocked to see ‘a computer’ get basic arithmetic wrong because they assume it’s actually computing data like everything else we’re used to in the digital world, rather than predicting plausible text outputs. This lack of predictability makes it very difficult to incorporate LLMs into existing code bases, with developers often having to add in multiple verification and correction steps to deal with inevitable ‘rogue’ outputs. Nonetheless, for bulk qualitative coding tasks, the amount of time saved easily mitigates the inevitable correction of such instances.
Here's another example experiment for a multi-stage coding tool to classify research funding opportunity tweets into academic disciplines. Using the twitter API to pull in the latest 10 tweets that contain keywords that might relate to research funding opportunities, the first step needed was to ask the GPT4 API (Chat GPT not viable because this was an automated process being done in bulk every few hours) to determine if this is actually a research grant opportunity, or whether it’s just someone tweeting about winning a grant, or a blog article on grant application advice for instance. So the initial prompt for each tweet was:
“Given the following tweet, determine whether it's an upcoming research funding opportunity that someone might be able to apply for (YES) or not (NO). If it is a research funding opportunity, the tweet should contain information about a call for grant applications, a research funding announcement, or other upcoming funding opportunities for research. Scholarships or charity or general public or business funding opportunities do not qualify as research funding. Some tweets might be about someone winning a research grant - this is not a research funding opportunity. Other tweets that aren't actual funding / grant opportunities might be announcing a research grant writing workshop, or any other topic not directly related to an upcoming research funding opportunity.”
The next step, assuming a tweet was deemed by GPT4 to be a legitimate research grant funding opportunity, was to classify it into a predetermined list of academic disciplines, which was taken from the Guardian’s University Rankings subject tables:
“Given the following research funding opportunity tweet, classify it into one of the following academic subject groups. You must not deviate from this list, you must pick the best subject classification from this list. If you can't be confident with a subject from this list, just return 'Unsure' instead. Here's the official list: { Accounting and finance, Aerospace engineering, Anatomy and physiology, Animal science and agriculture… }”
The results were then placed into an Excel file for human review. Below is a sample results table from this experiment with review and comments in the final column (right click and open image in new tab to see full resolution):
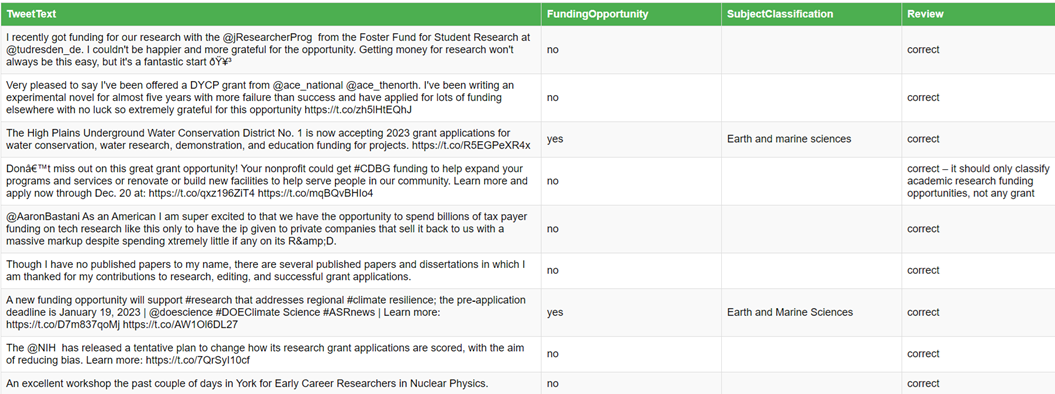
Ultimately, GPT4 is an advanced language tool so it’s not surprising that it’s very effective at working with qualitative text data, particularly with clear and explicit prompts and examples. It may require multiple pilot experiments with significant additional prompting and verification steps, but once you have a viable prompt there’s enormous potential for time saving in this arena, arguably more so than any other research task in this guidance.
Copyright considerations
Note the following excerpt from the Legal and Regulatory guidance regarding text and data mining permissions for non-commercial purposes - if in doubt always use MS Copilot or an LSE-only tool rather than risking sharing copyrighted data with a 3rd party commercial AI tool:
"Text and Data Mining: the TDM exception (Section 29A CPDA) permits anyone who has lawful access to in copyright material (e.g. through an institutional subscription) to make copies of it in order to carry out computational analysis for the purpose of non-commercial research. These copies must not be shared with any unauthorised users. Inputting licensed content from library subscriptions into GenAI tools can be interpreted as permissible computational analysis. However, if the tool retains copies of the inputted material this is likely to be interpreted as infringing copyright because it would be accessible to others not covered by the exception - also the TDM exception only covers TDM carried for research for a non-commercial purpose. Please, be aware that the interpretation and application of the TDM exception may be tricky at times, so be careful if you wish to resort to it, and if in doubt seek advice. When using GenAI with library licensed content, ensure the tool does not store inputs or use them to train data. If carrying out TDM on material licensed under Creative Commons check the terms of the licence to ensure compliance."