Introduction to APIs
The vast majority of use cases for GAI in research can reasonably be undertaken within a typical chat interface like MS Copilot or Chat GPT. There are tasks that make more sense to be automated however, and a common scenario in social science research is around qualitative coding, where you have a large number of small and similar tasks. It would be extremely onerous to paste these in one by one in a chatbot interface. Fortunately it’s possible to automate such tasks with code by using an API. API stands for ‘Application Programming Interface’, an umbrella term representing ways in which different digital systems translate and share data with each other. In this case, Open AI and Anthropic make their LLMs available via an API, meaning people can use whatever custom code and data they have and request LLM responses from the API in an automated way. Usages is charged per token so you pay based on usage rather than a monthly subscription fee that you get with Chat GPT.
One of the most important settings available in the API but not in the standard Chat GPT interface is the output ‘temperature’. You may have seen switches in Microsoft Copilot for ‘more precise’ and ‘more creative’ responses. The temperature setting ranges from 0 to 2, with lower values resulting in more deterministic outputs. The default temperature of Chat GPT is 0.7, so that can be considered a useful baseline that works effectively in most cases. For a creative writing task you may want to experiment with a temperature above 1, while for a strict classification task you may want to go as low as 0.1, which (roughly speaking) means only the top 10% of probable next token distributions will be used. Open AI offers a testing area called the ‘Playground’ where you can experiment with different temperature settings.
While Python is the recommended language to use especially for beginners (and especially because it’s GPT4’s ‘best language’ and is extremely good at explaining and teaching code as well as providing it), this section will use a ‘low code’ approach using Microsoft Power Automate, as its visual flowchart interface makes the logic easier to understand. Open AI has a very helpful Quick Start Guide on calling the API, including setting up your secret API keys (for authentication, authorisation and billing purposes) and some template code which is worth exploring, and of course feeding that documentation to GPT4 and asking it to build a tutorial is a great way to get started.
Coding open-ended survey questions
Open-ended questions are usually much more valuable for gaining insights into people’s subjective ideas, compared to pre-determined responses which also risk leading respondents in a direction that may not reflect their actual thoughts. The downside with open ended questions is that if you want to record any kind of summary statistics about the responses, it requires manually interpreting and coding, which takes a lot of time and effort.
LLMs are highly valuable tools in this regard and qualitative classification / coding in particular is one of the most useful labour saving tasks that they can support. Before the LLM revolution, natural language processing (NLP) required advanced machine learning, coding and data knowledge along with enormous effort to curage ground truth datasets and refining training and testing processes. Now, even the 2nd tier advanced LLMs are capable of classifying texts based on (good quality) natural language prompts, helping to democratise previously complex and onerous machine learning tasks.
Here’s an example of an open-ended question which would need to be coded qualitatively (MS Forms is used in this guide):
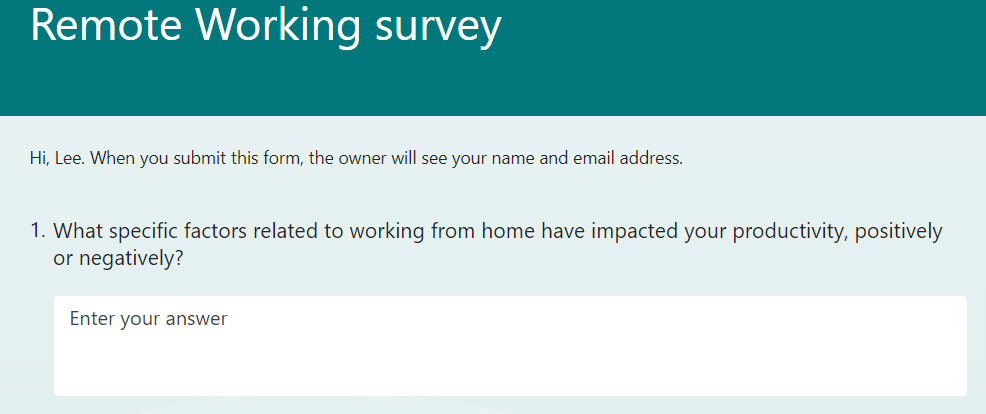
Let’s say based on your own research you’re interested in analysing the following themes, including an all-purpose ‘other’ category:
- Better Time Management
- Work-Life Balance
- Technology and Tools
- Communication and Collaboration
- Physical Workspace
- Flexibility and Autonomy
- Distractions and Interruptions
- Mental Health and Well-being
- Other
For simplicity’s sake given this guide is designed to illustrate the concept of automating qualitative coding, let’s assume that any response can only ever have a single thematic code. It’s of course possible to adapt the prompt to permit multiple or even multidimensional codes, but this requires additional complexity to join and split results in a structured way. An example prompt for GPT might be:
“You are a classification assistant designed to respond only with one of multiple pre-determined thematic codes. Your response can only be one of the permissible codes provided. You should not invent an alternative code, nor should you offer any thoughts or suggestions – the ‘Other’ classification is to be used if you’re unsure of if you encounter an error, I will check those cases myself so there’s no need for you to provide commentary. I will share a survey response relating to a social science study on people’s perceptions around working from home. The goal is to classify the survey response into one, and only one, of the following thematic codes: Better Time Management; Work-Life Balance; Technology and Tools; Communication and Collaboration; Physical Workspace; Flexibility and Autonomy; Distractions and Interruptions; Mental Health and Well-being; Other
Here's an example survey Response: Since working from home, I've found that I'm able to spend more time with my family, which has made me much happier overall.
Your output would be: Work-Life Balance”
The instructions may appear excessive but when a model is as advanced as GPT4, it can have a ‘mind of its own’ sometimes and try to be ‘helpful’ by responding in a way that doesn’t conform to instructions. This can be a problem with empty values or an error in your source data, which should always be prepared and cleaned in advance, but with large datasets it’s always possible for errors to creep in. Instructing the model not to provide commentary but simply default to an output which fits the pre-determined format will work well most of the time.
In this example we’ll use an Excel file stored on SharePoint as the cloud-based log to record responses and GPT4’s codes. Power Automate includes connectors to Excel and SharePoint making the integration simple for such a task. Here’s an example Excel table:

This updates in real time as and when survey responses come in. In reality there would be additional verification columns for human researchers to confirm or correct GPT4’s codes, but the main idea is that you can have a stream of GAI assistance to your qualitative data as it comes in. Here’s what the flow could look like:
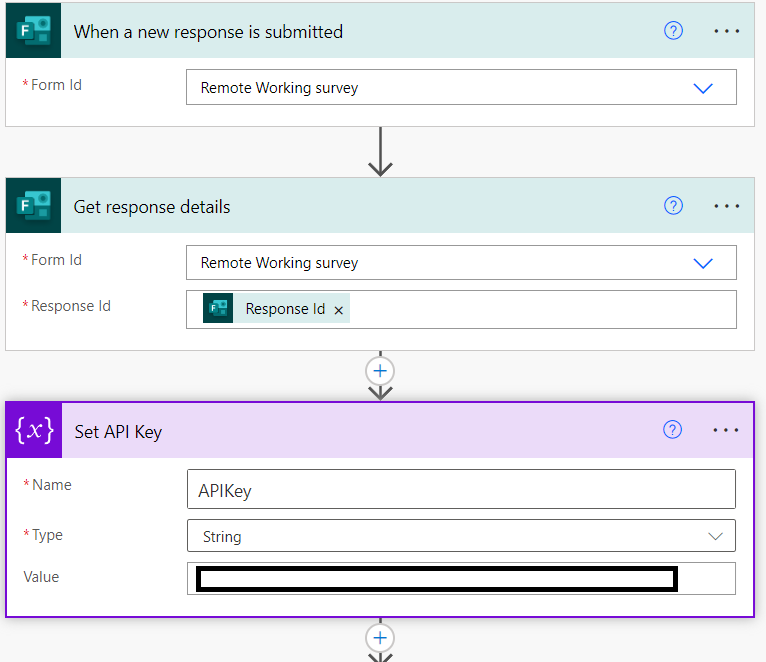
Part 1: Retrieving the response information from MS Forms and setting the secret API Key variable:
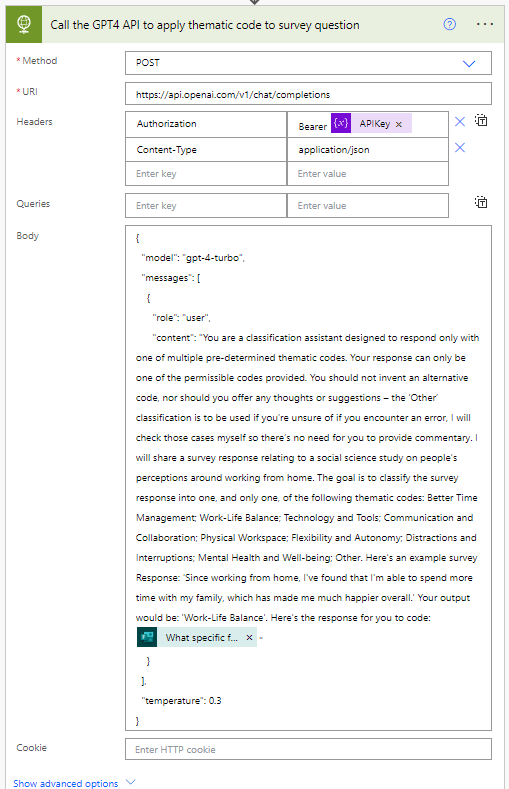
Part 2: Calling the API with the HTTP action and adding the survey question response:
Part 3: Parse the API response body (which includes lots of metadata we’re not necessarily interested in) to extract the content needed and add it to the Excel table along with the MS Forms data: 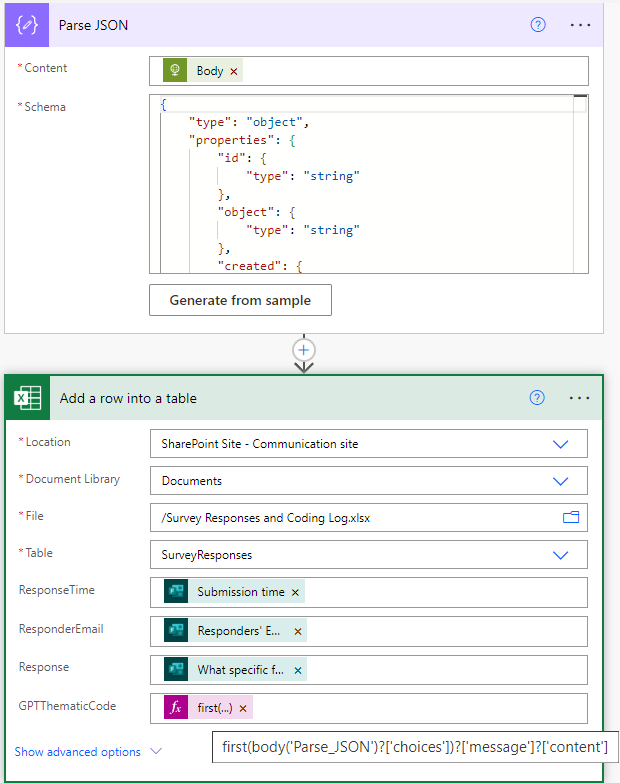
While this simple example used a low code approach with Power Automate as it makes it easier to explain, it’s worth re-emphasising that GPT4 (and similar class LLMs like Claude 3.5 Sonnet) is effective not only at providing working Python code based on your specifications, but also guiding and explaining it to you at whatever level of understanding, whatever level of detail, and based on whatever background you have which can help you learn more effectively. Python is ideally suited to advanced generative AI models because it's a very compact language (so it doesn't eat up too many tokens - LLMs still struggle with codebases beyond a couple of hundred lines) and is so widely used that the LLMs have lots of it in their training data. The entry barrier for learning to code has never been lower and it’s worth taking advantage as automating AI can significantly turbo-charge productivity. The main thing to be aware of as always is to avoid sharing personal data; while the API is what businesses use, Open AI still temporarily stores data for 30 days which among other security problems could violate GDPR.
Python API tutorial using Claude Sonnet 3.5
Here's an example using Python and the Anthropic Claude API, to perform bulk qualitative analysis (as opposed to the previous example which runs as and when a survey response comes in) based on CSV survey data. In this case it's just some generic brief analysis of each response to illustrate the point. Claude 3.5 wrote the python script (which can be run in the Jupyter notebook - the easiest way to begin with Python is to download Anaconda, this is a package which comes with all the main data science libraries pre-installed and makes the setup process simple).
Here's the dummy dataset being used, just 2 columns, the id and the raw survey response (in real applications you should of course thoroughly anonymise any data before sharing with the API):

The objective is to have Claude do some kind of initial qualitative analysis on each row, a task which would be extremely onerous to do in a chat interface copying and pasting each of potentially hundreds of responses. The prompt used for this tutorial is far too basic because it's for illustration purposes - being explicit about the exact type of analysis and especially providing examples (see the few-shot prompting section here) would be needed. The main point here is to show multiple types of qualitative output from an advanced LLM, including the key step of providing a direct quote from the source - as good as the best GAI tools are right now, they can never be trusted to be accurate, so verification is always needed. Getting the LLM to give you a direct quote means it will be easier for you to double check by doing a ctrl-F on the source data to make sure it hasn't fabricated anything. This 'show your working' requirement adds cost but it's always worth it.
The script below, as well as the dummy data, was generated by Claude Sonnet 3.5 itself - as long as you are explicit about your data source, column names, the kind of prompt you want and the kind of output you want, the model is very adept at producing short working scripts like this:
import csv
import anthropic
import time
# Initialize the Anthropic client
client = anthropic.Anthropic(api_key="your_api_key_never_reveal_to_anybody")
# Function to analyse a response using the Anthropic API
def analyse_response(response):
prompt = f"""Analyse the following response about political engagement:
"{response}"
Please provide:
1. A brief analysis of the respondent's level and type of political engagement (1-2 sentences).
2. A relevant quote from the response that supports your analysis. This is important to help me easily find the original response and help me verify your analysis.
3. A brief reflection on the implications of this type of engagement for democratic participation (1-2 sentences).
Format your response as follows:
Analysis: [Your analysis here]
Quote: [Relevant quote here]
Reflection: [Your reflection here]
"""
message = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=300,
temperature=0.5,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
# Read the input CSV file
input_file = "political_engagement_survey.csv"
output_file = "political_engagement_analysis.csv"
with open(input_file, "r") as infile, open(output_file, "w", newline="") as outfile:
reader = csv.DictReader(infile)
fieldnames = reader.fieldnames + ["analysis", "quote", "reflection"]
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
writer.writeheader()
for row in reader:
print(f"Analysing response for respondent {row['respondent_id']}...")
try:
analysis_result = analyse_response(row["response"])
# Extract analysis, quote, and reflection from the API response
analysis = ""
quote = ""
reflection = ""
for line in analysis_result.split("\n"):
if line.startswith("Analysis:"):
analysis = line.replace("Analysis:", "").strip()
elif line.startswith("Quote:"):
quote = line.replace("Quote:", "").strip()
elif line.startswith("Reflection:"):
reflection = line.replace("Reflection:", "").strip()
row["analysis"] = analysis
row["quote"] = quote
row["reflection"] = reflection
except Exception as e:
print(f"Error analysing response: {e}")
row["analysis"] = "Error in analysis"
row["quote"] = "Error in analysis"
row["reflection"] = "Error in analysis"
writer.writerow(row)
# Add a small delay after each row to avoid API rate limiting for large datasets
time.sleep(1)
print("Analysis complete. Results saved to", output_file)
Here's a screenshot of the final result:
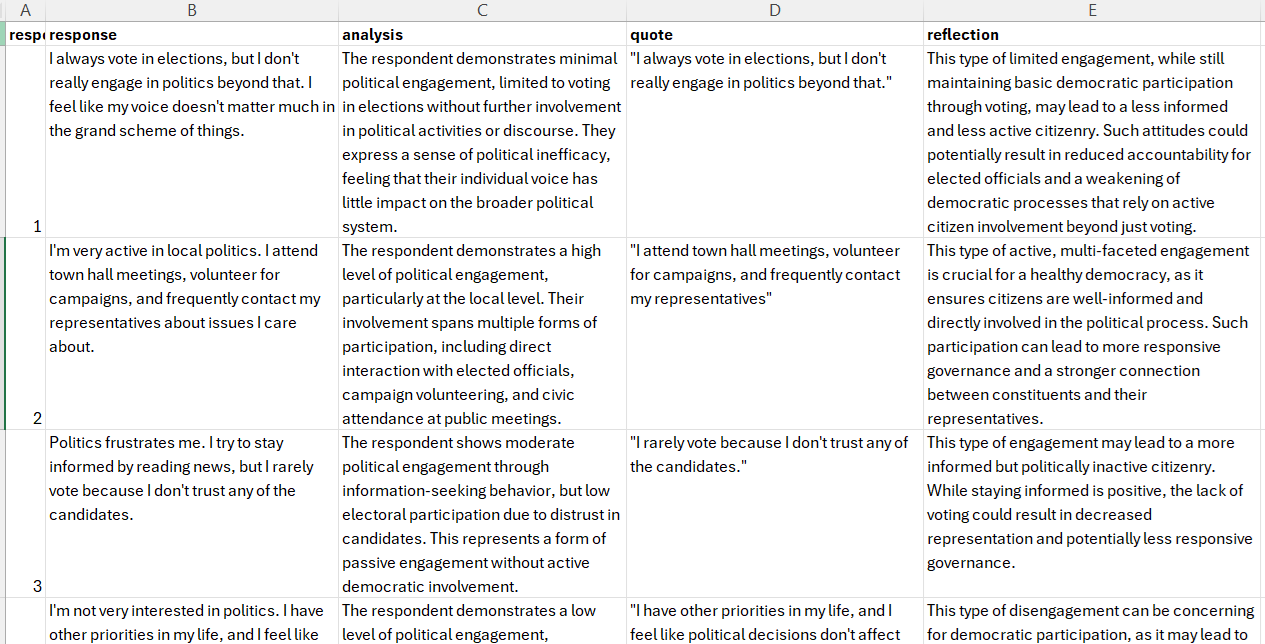
In a real scenario you would need substantial experimentation with prompting and evaluations on a small sample before running. The time saving compared to traditional 'from scratch' machine learning model development and ground truth curation is still spectacular, but given the versatility and nuance of natural language, prompt refining through experimentation is an essential part of the process (this applies to all GAI use but especially important for bulk operations like this).